Genetic Code
The genetic code is a set of rules or instructions that dictate how the information stored in DNA (deoxyribonucleic acid) is translated into functional proteins within living cells.
It is a triplet code, which means it operates in groups of three nucleotide bases, known as codons. Each codon corresponds to a specific amino acid or a termination signal for protein synthesis.
How does a Cell Interpret the Genetic Code
The journey of information transfer within the genetic code is a two-step process: transcription and translation.
- Transcription: The information in DNA is copied into an mRNA by the enzyme RNA polymerase.
- Translation: It is the process of converting an mRNA into proteins. Here the mRNA is read in groups of three, known as codons, that specify a particular amino acid or a stop signal. tRNA molecules bring the corresponding amino acids specific to each codon, allowing them to link together in a particular sequence. This chain of amino acids then folds into a functional protein.
The genetic code is the complete set of messages between codons and amino acids (or stop signals). Thus, the primary purpose of genetic code is to direct the synthesis of proteins based on the information in the DNA molecule.
How was the Genetic Code Deciphered
- From 1953 to 1956, Francis Crick and James Watson worked on the double-helix structure. They hypothesized that information from DNA is transmitted to proteins.
- In the mid-1950s, George Gamow deduced the genetic code to be composed of triplets of nucleotides. He was the first to propose that a group of three successive nucleotides in a gene may code for one amino acid in a polypeptide.
- Around 1961, the concept of codons was first described by Francis Crick and his colleagues. During the same year, Marshall Nirenberg and Heinrich Matthaei start deciphering the genetic code. They showed that the RNA sequence UUU specifically coded for the amino acid phenylalanine.
- Following the start of the discovery of the genetic code, Nirenberg, Philip Leder, and Gobind Khorana completed the rest of the genetic code and described all the three-letter codons for the corresponding amino acids.
Characteristics of the Genetic Code
1. Triplet Code (Codon)
As we know, a sequence of three nucleotides codes for a particular amino acid. Thus, the genetic code is a triplet. The four bases of nucleotide: adenine (A), guanine (G), thymine (T), and cytosine (C) make up all the 64 codons, including 61 coding for specific amino acids and three stop codons (UAA, UAG, and UGA). These determine the genetic code.
2. Universality
The genetic code remains the same for all living organisms, whether a bacterium, plant, or animal.
3. Non-Ambiguity
While multiple codons code some amino acids, each codon always specifies a single amino acid. Thus, the genetic code is unambiguous, ensuring that the instructions encoded in the code are clear and precise. The precise one-to-one correspondence between codons and amino acids is essential for accurately synthesizing proteins that carry out various biological functions.
4. Redundancy and Degeneracy (One Amino Acid, Many Codons)
The genetic code employs a degree of redundancy, where multiple codons can code for the same amino acid. All four codons, CCU, CCC, CCA, and CCG, encode the amino acid proline. It is crucial because it minimizes the harmful effects of incorrectly placed nucleotides on protein synthesis.
This redundancy is not arbitrary; it results from the ‘wobble’ phenomenon—a property in which the third nucleotide of a codon (the ‘wobble position’) can be flexible in its base pairing. It allows a single tRNA molecule to recognize and bind to multiple codons, enhancing the efficiency of protein synthesis. The wobble property also provides a buffer against errors during transcription and translation, contributing to the accuracy of protein synthesis.
5. Polarity
Each triplet is read from the 5’ → 3’ direction. The first base is always 5’, followed by a base in the middle, and then a 3’ base. Thus, the codons have a fixed polarity.
6. Start and Stop Codons
Within the genetic code, there are specific codons that act as ‘start’ and ‘stop’ signals for protein synthesis. The start codon, AUG, codes for the amino acid methionine and marks the beginning of protein synthesis.
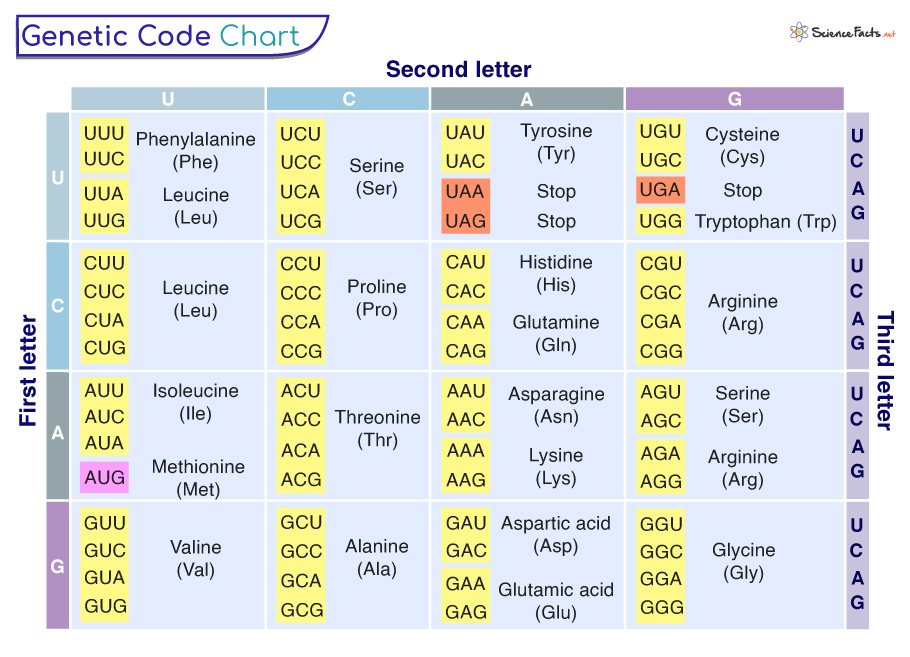
Stop codons (UAA, UAG, and UGA) signal the termination of protein synthesis, ensuring the protein is released from the ribosome in its complete form. These signals play an essential role in regulating the initiation and termination of protein synthesis.
As messenger RNA (mRNA) directs protein synthesis when ribosomes synthesize proteins, the standard genetic code is originally represented as an RNA codon table organized in a wheel.
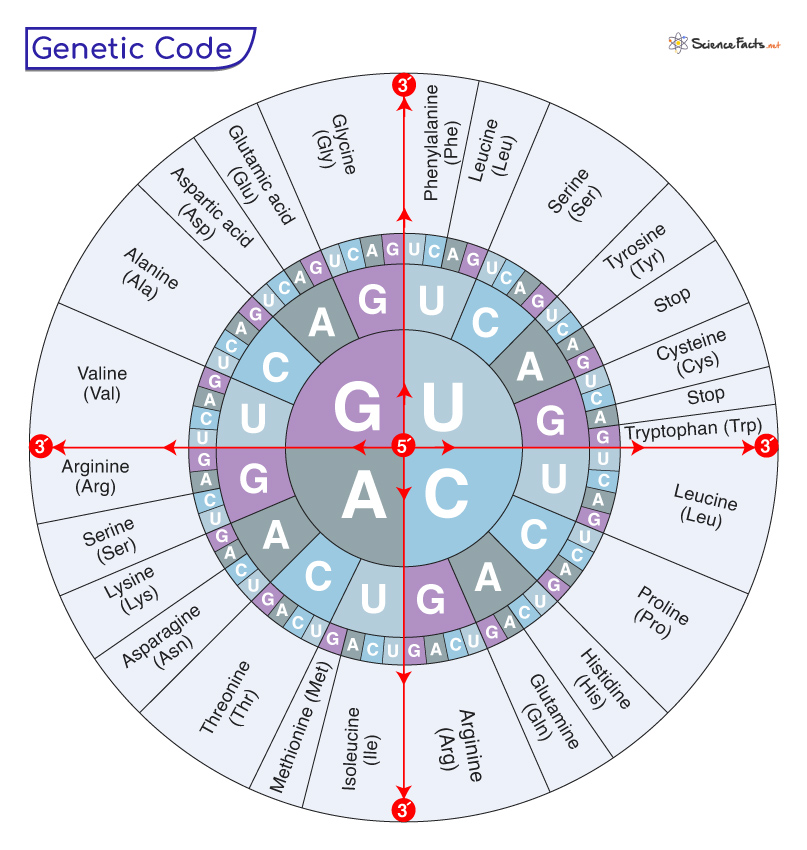
7. Reading Frame
The start codon is always crucial because it determines where the translation will begin on the mRNA. It also determines the reading frame, which codes for the subsequent amino acids.
The same sequence of nucleotides can encode different polypeptides depending on the position of the start codon and, therefore, the frame in which the codons are read.
Alternative Genetic Code
The genetic code is universal, with codons coding for a fixed number of amino acids and similar START and STOP signals in the genes. However, there are some exceptions to this rule.
They are:
- Attributing one or two of the STOP codons to an amino acid
- Both GUG and AUG can function as start codons, although GUG codes for valine
- The genetic code in mitochondria differs from the standard genetic code used in the cell nucleus
-
References
Article was last reviewed on Wednesday, September 13, 2023
Related articles
Popular Articles
Join our Newsletter
Fill your E-mail Address